Selective Delays in SPARK and Ravenscar
A “selective delay” in Ada is a concurrency idiom where a task can wait for a message to be received, but then abort the wait and perform some other action if a certain time has passed while waiting. So basically “receive a message with a timeout”. When you enable spark (and consequently the Ravenscar concurrency restrictions) this is not allowed anymore because it uses features that count as “unsafe”.
We saw a variant of this selective delay in a previous article, and you can view this one as a more advanced continuation of that concept. This article is also more well written, so you may just want to read this instead.
I’ll describe a safer version shortly, but first, here’s how it’s often done in standard Ada 2012.
Ada 2012, No Restrictions
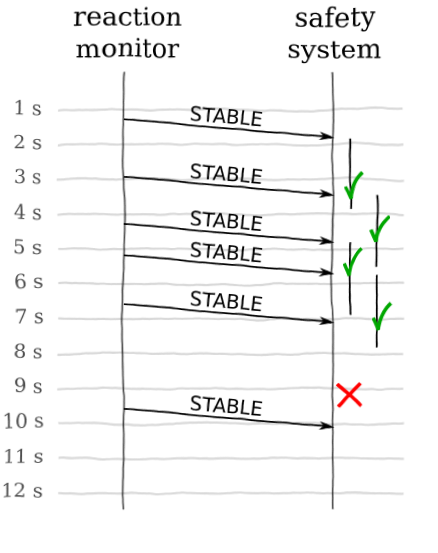
Figure 1: Illustration of our safety system
We’re looking for something along the lines of the image here. In order to get it, let’s jump straight into the code, and I’ll explain it as we go along.
with Nuclear_Reactors; use Nuclear_Reactors; package Nuclear_System is
We have a package Nuclear_System which is a mission-critical
piece of some hardware we’re building.
type Nuclear_Reaction is (Stable, Uncontrolled);
This is a type representing some sort of events which can happen in our system.
task Reaction_Monitor;
We have one task that monitors our physical system and emits the above events as soon as they are available. This may be at irregular intervals, so the time that passes between two events may be anything from 0 to infinity. If it takes longer than 2 seconds to get an update, though, something could be very wrong (like the reactor has burnt up and taken with it the monitor).
task Safety_System is entry Current_Status (Status : Nuclear_Reaction); end Safety_System;
This is a separate task that receives these events and takes proper action depending on what they are. This includes reacting if too long has passed since the last update.
end Nuclear_System; package body Nuclear_System is
That’s all for the spec, so let’s see what the implementation looks like.
task body Reaction_Monitor is
begin
loop
delay Random_Duration;
Safety_System.Current_Status (Stable);
end loop;
end Reaction_Monitor;
The “monitor hardware” in our system is a task that waits for a random
amount of time (Random_Duration is a magic function that returns a random
duration between zero and three seconds every call). When that amount of time
has passed, it sends a “nuclear reaction is Stable” message to the
Safety_System.
task body Safety_System is
begin
loop
select
accept Current_Status
(Status : Nuclear_Reaction)
do
case Status is
when Stable =>
null;
when Uncontrolled =>
Nuclear_Reactors.Shut_Down;
end case;
end Current_Status;
or
delay 2.0;
Nuclear_Reactors.Emergency_Stop;
end select;
end loop;
end Safety_System;
The Safety_System is the more interesting bit. In a continuous
loop, at each iteration it waits to receive an entry call to
Current_Status. If it’s received, it inspects the status and performs the
appropriate action:
- If the reaction status is
Stable, nothing needs to be done. - If the reaction status is
Uncontrolled, we initiate a graceful shut down of the reactors. - If two seconds have passed since the last status message, we assume the worst and initiate an emergency stop of the reactors to ensure no disaster occurs.
end Nuclear_System;
That’s the entire package!
SPARK 2014 (with Ravenscar)
Since we’re interested in expanding our operation beyond the bathtub experiments we have made, we need to comply with local regulations when it comes to nuclear activities. As it turns out, our local authorities require us to write the controlling software in spark to ensure the lives of our children.
Saying that something is “in spark” is really just a fancy way of saying “using the subset of Ada 2012 that the spark tools can prove”, so translating our Ada 2012 program shouldn’t be too hard, and we can do it piece by piece.
There are some things we need to consider when we rewrite our package in spark. The primary limitations we’ll encounter lie in Ravenscar, which is a set of restrictions on concurrency in Ada with the goal of making the result of programs more predictable and avoiding typical common errors in concurrent code.
For example, in our spark code we are no longer allowed to have
select statements, which means tasks can only wait for one message
at a time. We can’t use relative delays either – we have to specify a specific
point in time when the code should resume. We can’t have side-effects in
functions and expressions.
This touches on basically all the things we used in our initial architecture, so we have to come up with an alternative architecture. The basic idea consists of three things:
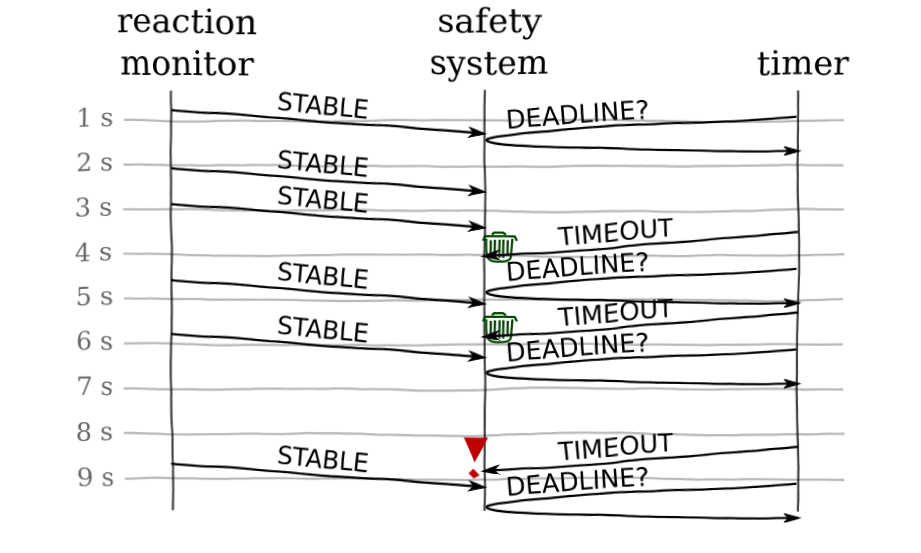
Figure 2: The safety system in spark
- We keep the
Reaction_Monitortask. It continuously monitors the reaction and pipes status messages into theSafety_Systemjust like before. - We change the
Safety_Systemfrom being a task to being a protected object (essentially an object which only one other process can update at a time.) - Since we loose the “real-timeyness” of
Safety_System, we also include a littleTimertask whose only responsibility it is to activateSafety_Systemafter X amount of time has passed.
This is the result!
pragma Partition_Elaboration_Policy (Sequential); pragma Profile (Ravenscar); with Ada.Real_Time; with Nuclear_Reactors; use Nuclear_Reactors;
The pragmas set a sequential elaboration policy and enable the Ravenscar profile to reduce concurrency issues, which is required in spark code.
package Nuclear_System with SPARK_Mode is package RT renames Ada.Real_Time; use type RT.Time;
The Nuclear_System is in spark, so we specify that with the SPARK_Mode
aspect. Since spark prohibits relative delays, we need a way to specify an
absolute time at which the process should wake up again. We’ll do this with the
Ada.Real_Time library.
task Reaction_Monitor; type Nuclear_Reaction is (Stable, Uncontrolled);
The Reaction_Monitor task is unchanged from before, as is the status
message type.
protected Safety_System is
The Safety_System is a protected object this time.
procedure Current_Status
(Status : Nuclear_Reaction)
with Global =>
(Input => RT.Clock_Time,
In_Out => Nuclear_Reactors);
This is required information, and it’s telling spark that the result of the
Current_Status procedure may depend on the wall clock time (which is true – the new
Deadline is calculated based on the current time), and that it may affect the
Nuclear_Reactors too (which is also true – we may shut them down if the
reaction is out of control.)
The benefit of specifying this information is twofold: First, it tells other
programmers that they can expect different results from this procedure if it is
called at different points in time. Second: if we accidentally shut down the
reactors in a procedure that isn’t supposed to, spark will throw an error
message saying “hey this procedure can affect Nuclear_Reactors and you
haven’t told me it should!”
entry Get_Deadline (Time : out RT.Time);
procedure Timeout
with Global =>
(Input => RT.Clock_Time,
In_Out => Nuclear_Reactors);
private
Deadline : RT.Time := RT.Time_First;
Timer_Active : Boolean := False;
end Safety_System;
We need to define legal values for all variables in protected objects for our code to be valid spark. This avoids problems of accidentally reading variables before they are defined.
task Timer
with Global =>
(Input => RT.Clock_Time,
In_Out => Nuclear_Reactors);
This is the Timer task. The purpose of this will be more clear
when you see the implementation. The Timer task will not directly
infuence the Nuclear_Reactors, but it will make calls into the
Safety_System that do.
end Nuclear_System; package body Nuclear_System with SPARK_Mode is
So what does the code for these things look like? Well for one, the body of our package is also in spark. We have to specify this separately, because we can have just the package spec in spark, with the weaker guarantees that imply.
task body Reaction_Monitor is
begin
loop
delay until Random_Wait;
Safety_System.Current_Status (Stable);
end loop;
end Reaction_Monitor;
Well, the monitor task is basically the same as before. This magic
Random_Wait function is not legal spark code, but since it’s only part of our
model and not our real nuclear system that’s okay.
task body Timer is
Deadline : RT.Time;
begin
loop
Safety_System.Get_Deadline (Deadline);
delay until Deadline;
Safety_System.Timeout;
end loop;
end Timer;
This is all the Timer task does. It gets the latest deadline from the
safety system, it delays until that time, and then wakes the safety system up
to ensure something happens if there have been no status updates in the
expected time.
You can read that as “Hey, when should I remind you?” “At 8:12, please” …time passes… “Okay it’s now 8:12, and you wanted me to remind you”.
protected body Safety_System is
procedure Current_Status
(Status : Nuclear_Reaction)
is
Current_Time : RT.Time := RT.Clock;
begin
Deadline := Current_Time + RT.Seconds (2);
Timer_Active := True;
case Status is
when Stable =>
null;
when Uncontrolled =>
Nuclear_Reactors.Shut_Down;
end case;
end Current_Status;
When the Current_Status procedure is called, it’s because a message has been
received, so every time that happens we set the deadline for the next message
to whatever the current time is plus two seconds. We also set Timer_Active to
true, and you’ll see why shortly.
Then we handle the message the same way as before.
entry Get_Deadline (Time : out RT.Time) when Timer_Active is begin Time := Deadline; end Get_Deadline;
This is why we had the Timer_Active variable. The Get_Deadline call will
block until Timer_Active is true, which means the Timer task will not keep
track of time needlessly – only when it’s asked to do so.
We could make Timer_Active a function that checks if RT.Clock <
Deadline. Either way works. You can also specify spark assertions that ensure
the two formulations never differ.
procedure Timeout is
Current_Time : RT.Time := RT.Clock;
begin
if Current_Time >= Deadline then
Timer_Active := False;
Nuclear_Reactors.Emergency_Stop;
end if;
end Timeout;
end Safety_System;
end Nuclear_System;
At this point, a call to the Timeout procedure does not guarantee an
actual timeout has happened, because the Deadline may have been updated since
we started the timer. This is not a big problem, though. We just check if the
deadline has actually passed, and if so take the proper action. If not, the
timer will go on to get the new value for Deadline and count down to that
instead. This works because the Deadline will only ever grow larger; it will
never decrease. Obviously, we should write spark predicates and prove that this
is indeed the case.
Conclusion
The reason I’m writing this article to begin with is that I faced this exact problem; I had a selective delay based message accept timeout, and I wanted to write that code in spark. There are some mentions of the problem on the basic Google searches, but no complete solution. So here it is, for anyone in the future with the same problem.
I realise now that this article might double as a really bad advertisement for spark; we had to change a lot of code to make it legal spark. Normally, getting started with spark is much easier. If you’re careful about it, you can sparkify only small parts of your code base at a time. The reason it looks complicated in this article is because the program I started out with basically consisted of 100% illegal spark code. That’s not representative of a normal application.
Maybe “look how easy it is to introduce spark in existing projects” is a separate article, but I can’t promise anything.