Parallel Agile: Interesting Idea – Does It Work?
Parallel Agile1 Parallel Agile – faster delivery, fewer defects, lower cost; Rosenberg, Boehm, et al.; Springer; 2020. promises to teach nine women to produce a baby in a month. Or, if you’re really in a hurry, 27 women in 10 days. Or any other combination that suits your specific staffing/time demands.
You might guess that I’m a bit skeptical of the results, but it’s co-authored by Boehm. I have to give it a chance.
The authors argue that more programmers can result in faster completion if one allows rapid prototyping against a shared domain model, and decomposes a system into somewhat independent use cases early on, assigning one use case to each programmer. The combination of a flexible, shared domain model and just the right amount of planning, they claim, allows each programmer to focus on their small piece of the puzzle, and the pieces will line up fairly well for integration when finished.
In graphical form, the software is then structured as such:
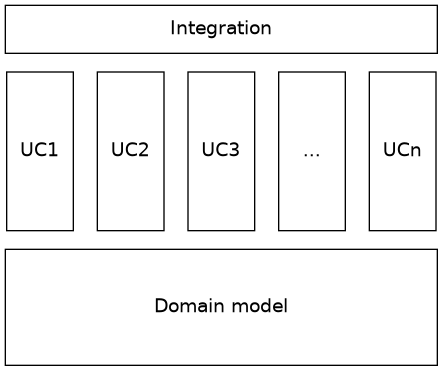
The base is formed by a rich domain model, independent use cases build on that, and then a small effort to integrate it all is needed at the end.
The authors imagine this can be built in three cycles, with
- The first cycle focusing mainly on validating the domain model by prototyping use cases;
- The second cycle focusing on completing the use cases, including fleshing out control flow variants with some integration; and
- The third cycle focusing on integrating, testing, and optimising.
So, does it work? Heck if I know. But we can still learn from it.
The evidence is sparse
The authors’ claims aren’t plucked entirely from thin air. Rosenberg and Boehm have run a small number of software projects programmed by university students using this approach, and they consider these projects successes. Student projects notoriously have 100 % staff turnover every semester, and students may not be very experienced programmers; this lends their story credibility. In their professional past, they have also run other large projects along similar principles, with good results. Unfortunately, this is also about where the evidence stops.
Let’s go into what the Parallel Agile approach builds on, and why the authors think it works.
Up-front domain design is core to the idea
It’s easy to speed up a software project2 In the litterature known as compressing the schedule. by adding more programmers to it: all one has to do is decompose the system into more independent parts, and assign one part to each programmer. Done. This has been known at least since the 1950’s, and is not new.
But that’s also not the difficult bit. What’s difficult is decomposing the system into that many independent parts, and then integrating all parts together into a unified whole. I have written before about why I think it’s better to decompose into fewer parts, rather than more parts. The authors of Parallel Agile think there are two keys to solving this decomposition problem.
Before any programmers are assigned work,
- Design a relatively complete domain model3 A domain model is, loosely speaking, the universe defined by the software, the names of all objects that it’s going to have.; and
- Write down a relatively complete set of use cases4 A use case is essentially a small feature slice..
Then give every programmer one use case each, and tell them to only integrate through the domain model (i.e. effectively instruct them not to talk to each other too much, and just trust the integrity of the domain model). If done properly, this really should work, because each use case is somewhat independent of the others, and technically it is possible to integrate everything via the domain model – and it would yield very decoupled code, to boot.
This is where I sense one of the potential flaws of the idea. The code might turn out to be excessively decoupled; things that should share code and/or data will be developed completely independently. This means duplicated effort during initial development, and if the duplication is not reconciled during integration5 Which it sort of cannot be because then Amdahl’s law will constrain the scalability promises of Parallel Agile., then this cost becomes interest paid on technical debt with continued development. In some cases6 A very tight deadline with fierce financial penalty, for example, or a classful of cheap student programmers to throw at the problem. that tradeoff might be worth it. I’m not sure it saves money in the long run for most projects.
Note that not even the authors imagine that they can design a complete domain model up front, but they believe that with very little effort, it’s possible to get, say, 80 % of the way there. The remaining 20 %, they seem to imply is likely to be mainly about private attributes and things that are relevant for specific use cases only, so they can be filled in by the programmers as they go about their day.
Similarly, the authors admit that some uses cases may be discovered only once programming has started. The nature of task assignment (one use case per programmer) naturally means some programmers will finish their tasks early – these will be the reserve force that handles newly discovered use cases as they come up. That part sounds sensible.
Development proceeds in two phases
The authors say there are three phases to a Parallel Agile project:
- Proof of concept: prototype-driven requirements discovery
- Minimum viable product (mvp): Model-driven design
- Optimisation: Acceptance-test driven release strategy
Nice picture, but not how it appears to have worked for basically any of the actual projects presented in the book. There seems to be little qualitatively different between these phases, which is also admitted by the authors when they say that “part of the goal of this phase was carrying over and completing unfinished work from the last phase.”
Another problem with the three-phase picture is that it makes the common, but incorrect assumption that programmers develop software until it is finished, and then they switch over to maintaining it. In my experience, software is not an event that happens and then it’s over – it’s a continuous process. It’s impossible to divide a continuous process into three distinct stages, especially up front. (And indeed, at least one of the authors’ own projects seem to be progressing into a fourth phase with continued development. I suspect there will be a fifth, and a sixth, and so on, until the project is abandoned.)
At some points the authors even call these phases sprints, and that was when the penny dropped for me. That’s what they are. They are fixed-time7 Due to the inflexible length of university semesters. iterations, not phases.
However, it seems to me there are two separate phases. But we can call the first phase the zeroth phase since the authors don’t admit it as a real phase of development.
0. Domain Design
The Parallel Agile approach rests on a relatively complete domain model and use case descriptions. These don’t drop out of thin air when you need them. In fact, the ability to develop these accurately is going to be what the entire project stands or falls on when following the Parallel Agile approach.
That’s another flaw I suspect of the approach. The authors do admit that sometimes you don’t know what you need until you have seen what you don’t need. The authors encourage programmers to revise the domain model and use cases if they are discovered to be a bad market fit halfway through the implementation. However, due to its massively parallel nature, a Parallel Agile project has expended a lot of resources on an invalid approach if that happens. The authors themselves don’t offer any sign that they had to significantly pivot a core idea of the project, only that they had to throw out auxiliary requirements.
I may be biased here. I come from a part of the industry where it’s not unusual to need to work on something for two months to discover it is the wrong approach and have to start over. In that situation, it’s nice to make small bets at first, and then raise the stakes only when there is some indication of a market fit. It comes as no surprise to me, then, that the book describes some features that were developed without any market validation whatsoever.8 At least not that the reader is made aware of. In particular, they talk about an integration into the workflow of emergency services. I know how slowly that industry moves, and I highly doubt they’ve agreed to try out a prototype smartphone app written by univesrity students. Lacking the market buy-in would be a huge opportunity cost in a competitive environment, but does not matter for a fun project for students.
That said, there may be parts of the industry where requirements are more certain: new systems that replace existing ones, well-specified projects for safety-critical systems, repeatedly making similar content management systems, etc. Those things sound like they could be good fits for Parallel Agile.
The authors claim the initial domain modeling (i.e. this entire zeroth phase) can be workshopped in a few hours with domain experts and senior programmers. But on their own projects, they also admit they have pondered the design for a few months before starting on it. I think that says it fairly well: assuming domain experts that have been thinking about the problem for a while, I’m sure one can get a rough approximation of a domain model in a few hours. Will it be the correct domain model? Only implementation can tell.
1. Incremental Programming
This is where the authors have an ace up their sleeves. They have made a tool that converts a domain model into a set of networked, autoscaling microservices in the cloud. You give the tool a uml diagram of all the objects in your application, and it gives you back a set of url_s that support _crud operations for all objects in the diagram, with the correct attributes, relationships, and everything.
This means you don’t have to write database access code, you don’t have to write the domain object classes yourself. If you change your domain model, you run the tool again and it automatically creates/deletes/migrates microservice data to reflect the new model.
Let’s be clear on what this is: this doesn’t do anything a group of programmers couldn’t do. It does exactly what they would do, except it does it much, much faster. My default stance towards “technology that makes X go faster” is to ask, “Does it provide a qualitative difference to the entire effort or will it just make X go faster?” The authors seem to believe that needing only minutes create and update code that mirrors domain models is a qualitative difference, and what makes it possible for developers on individually assigned use cases to update the shared domain model if they need to. They go so far as to claim that without MongoDB and microservices, Parallel Agile would not be possible.
I’m not as quick to buy the promises of modern technology to qualitatively change our lives. However, this generation of low level code certainly is quantitatively effective, because domain model code is probably one of the sequential aspects of the project, so any speed gained there means Amdahl’s law has a looser grip around the throat of the schedule.9 In fact, later in the book they admit that they suspect one of the large factors that makes Parallel Agile work is that they have been able to automate two of the time-consuming sequential parts (writing code for the domain model, and creating automated acceptance tests). This is stuff that would otherwise feed Amdahl’s law.
On integration, the authors make two points that are worth reemphasising:
- They make extensive use of testing in parallel with implementation and building an evolving corpus of acceptance tests to ensure both that the functionality works as desired, but also that programmers don’t step on each other’s toes accidentally when they integrate through the domain model.
- Although not mentioned explicitly, it also sounds like they have some programmers working not with specific use cases, but with helping other programmers integrate their efforts with the rest of the software.
I think both of these points are important for the approach to succeed.
Parallel discovery of alternative requirements
The authors mention in one or two situations when they were faced with technical decisions of high uncertainty that they evaluated multiple approaches. However, it sounds like they evaluated these approaches sequentially, i.e. tried the most promising first, and then if it failed to pan out tried the second one.
Essentially, Parallel Agile is a way to run a project at huge cost (many salaries to pay), in exchange for some certainty that the project will be finished to a tight deadline.
There could be another way to use the ideas of Parallel Agile, and I’m not sure if the authors have discarded that idea, or simply not thought about it. Instead of starting from 40 use cases where one thinks all 40 will make it into the final product, assigning one use case to each programmer, one could start from a smaller core of 20 use cases, and then on average try two variants of each – still all in parallel.
That way, we would still be effectively implementing 40 use cases, only some of those use cases would implement similar functionality from a user perspective, only taking different approaches. We will get fewer features in, but on the other hand, we will have a greater probability of having each functionality work10 If there’s only a 70 % probability that any particular approach to a feature works, and we try four different ways, then there’s a 99 % probability at least one them works. This is essentially the promise of set-based concurrent development, which I’d like to understand better.. Since we focus on a smaller core of use cases, there will also be a lower effort required to integrate them.
Exploring multiple alternatives to the same thing in parallel is guaranteed to result in work that needs to be thrown away (to the horror of managers all around), but it is more likely to result in a successful product. It is a way to scale up effort, not to speed up implementation, but to speed up requirement discovery and thus reduce risk quicker.
In the part of the industry where I’m from, it should be more important to pay to reduce risk than to speed up implementation. But then again, that’s still a harder pill to swallow for management types.
Summary
I realise this review may sound harsh and that’s not really my intention. When the authors say they are astonished by the results they’ve had, I trust them. I’m genuinely glad they’re sharing their discoveries. The book has given me a lot of good ideas for how I can improve my processes. But I’m also sensing inconsistencies in how they present their approach, and quite a lot of arguments against the straw man version of alternative approaches.11 Things like “timeboxing is bad because people mistake timeboxes for tight deadlines” or “unit testing is bad because people focus too much on statement coverage”. Yes but no. I don’t think the authors do this by mistake, I think they are trying to correct common misconceptions but for someone like me who does not share those misconceptions it comes off as disingenious. That unnecessarily clutters the authors’ main points.
My main takeaway from the book is perhaps not that there is a magic wand to make nine women produce a baby in a month (there may or may not be), but rather that the authors very successfully reinforce the importance of developing a domain model, and then being insistent that most integration should go through it. I believe that is helpful advice regardless of whether you use Parallel Agile or not.
However, I’m also not willing to write off the idea entirely. Here’s what I want to try in a personal project, if I stumble over one that seems well suited to it:
- Start by modeling the domain and use cases that woud be present in an initial version.
- Stub out storage and api code for domain objects.
- Develop incrementally:
- Work strictly on one use case at a time, filling in the storage and api code as necessary. Create the use case as an independent deployment unit.12 Possibly also try spending more time diagramming than I usually do before hitting the keyboard.
- In parallel with the above, develop automated acceptance tests.
- Integrate the independent use cases with each other.
This is, if I’ve understood it correctly, the core of Parallel Agile and if it works well for 30 developers in parallel, then it ought to work well also just for the one developer doing 30 things in sequence. Modus tollens, if it doesn’t work sequentially, then there is no way it could work in parallel.