Common Mistakes in Modularisation
This article1 Alternate title: The Software Design Tree and Program Families. leads to two rather simple ideas.
- Design decisions have consequences on other design decisions. This is an important aspect of how and when to decide things.
- Modules can be used to hide design decisions so they no longer affect subsequent decisions.
I will try to explain how this comes about, some consequences, and some mistakes to watch out for. But first, we need to visualise the effects design decisions have on other decisions.
The design space tree
We can think of the design space as a tree.
- The decisions near the leaves of the tree are about concrete things that don’t
affect much of the rest of the design.
- What input encoding do we use?
- What is the colour of the button?
- How long is the timeout?
- On the other hand, high-level branch decisions near the trunk of the tree
severely constrict the solutions that are possible. These are the significant
decisions that are incompatible with a large number of potential solutions.
- How much memory can we use?
- Which problems will we avoid solving?
- How much control will we give the user?
The path we take through the tree – i.e. the design decisions we make – result in a specific product being designed.
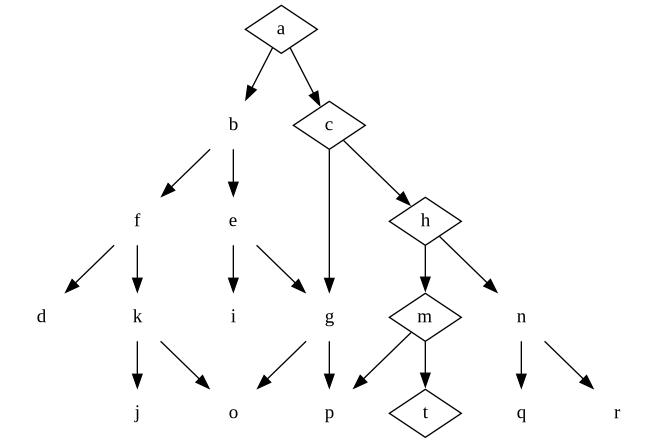
In this example, we have created the product implied by our decisions in questions a-c-h-m-t. Notably, the decision we made in question a took us down the path to c, which means it also eliminated the potential solutions that involve decisions in question b.
This is why it’s useful to start with the high-level questions: it eliminates the parts of the design tree we think are irrelevant, and lets us focus on the relevant questions. It gets us to market faster, and we can learn quicker which decisions we got wrong.
Configuration options create multiple products
In the software world, we don’t generally end up with just one product. We end up with a configurable product, which is the same as a large number of products that behave slightly differently; with the specific product desired at any given moment selected by configuration options.
This is true, but immaterial to the following analysis. We can pretend that the final leaf node represents not just one product, but all products that can be generated by making configuration adjustments.
The mistake of focusing on concrete details
When we are new to product development, we often dig into the concrete details right away. This means we make decisions near the leaves before we tackle higher level decisions. Halfway through the development work (i.e. when significant amounts of code has been written already), we may have a design tree that looks like this:
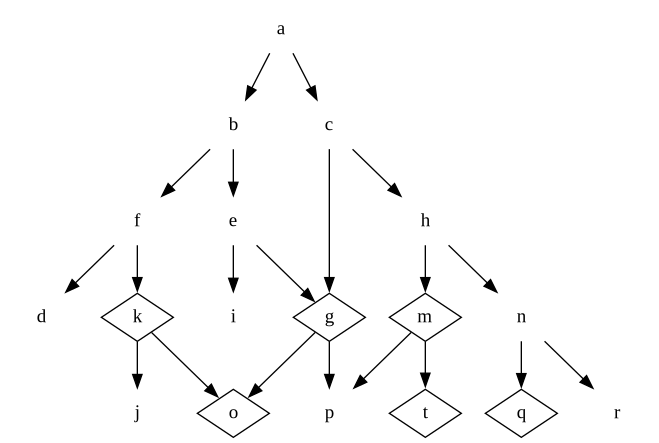
What product does that correspond to? None at all. These decisions are on completely different branches, meaning they are mutually exclusive, and there is no way to construct a product that satisfies them all. We generally don’t notice this until someone forces us to make a decision on e.g. question b, and then we realise that whatever we choose, we are locking ourselves out of either k or g.
The silver lining on the dark clouds is that this is usually discovered rather late in the development process, so at this point the stakeholders may actually be receptive to throwing out most of the decisions we had agreed to in order to make the project finish sooner. It is a little embarrassing none the less.
Sometimes we are lucky and by accident make coherent leaf-level choices, e.g. like this:
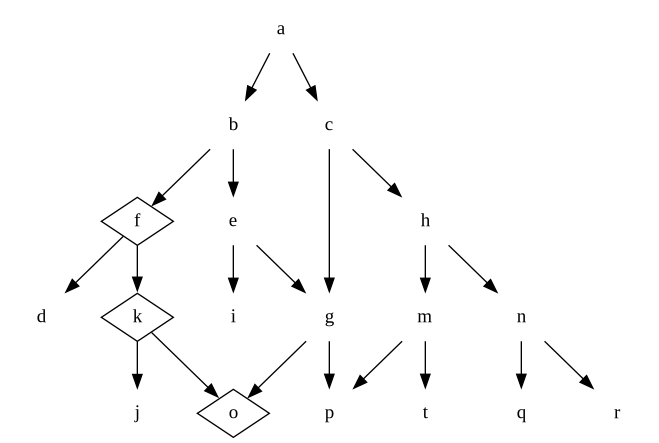
But then when we get around to discussing question a, we realise we would much rather make the choice that unlocks c as an alternative. Unfortunately, that’s incompatible with all decisions we’ve made so far.
This is a devious situation that occurs surprisingly often: our early leaf-near decisions imply a set of higher level decisions that we disagree with. Again, we usually don’t discover this until we are trying to integrate everything and get it out the door. Result: lots of expensive rework, or settling for a suboptimal solution.
This is another reason to focus on high-level decisions first: we lower the risk of spending time on decisions that we’ll have to tear up later because they are incompatible with the overall shape we want the product to have.
We focus on leaf decisions because it feels good
The reason we tend to focus on leaf-near decisions, I speculate, is that concrete details
- engage a lot of people because they are easy to understand; and
- quickly give us a sense of progress.
When we focus on concrete details while ignoring the big picture, we can work off ticket after ticket and show great velocity when the project starts. This is good for getting promoted.
But this also means we make these mistakes more often under time pressure, and/or when many people are involved. These are the situations in which we most would like to avoid rework! We can do better.
The very early parts of the project is not the time to make decisions on details. Leave the details open.
Changing requirements result in abandoned paths
Let’s imagine we overcome these difficulties2 Either by designing a coherent product from the start, or by regretting some of our early decisions and unwinding them. and we have a working product. Guess what happens next?
The requirements change!
It turns out what users really wanted was the product that comes out of the decisions in a-c-h-n-q instead. We backtrack, tear out some code, write new code, refactor, and we end up with a new set of design decisions.
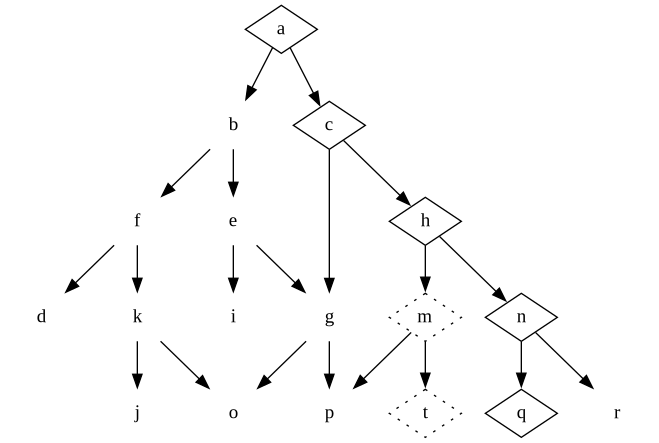
Only then we discover the users may actually want a-c-h-m-p instead!
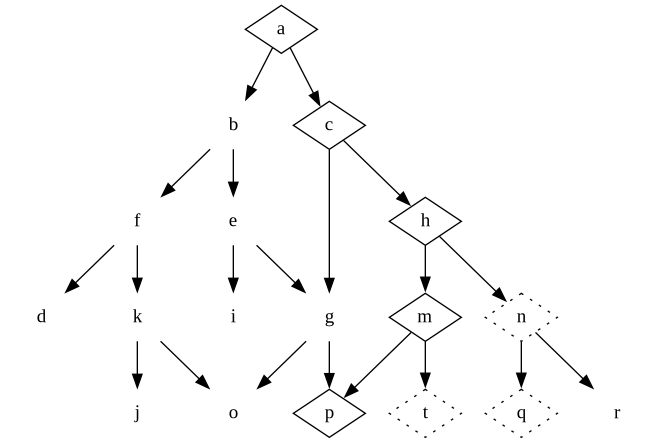
In some businesses, we are lucky and can at this point say, “There. This is your finished product. Go off and have fun with it.” In other businesses, this process never ends; we keep discovering new requirements and – hypothetically – walk around the design tree forever.
In practise we never end up walking the design tree forever. Residue from our past mistakes (the dotted nodes) lingers in the codebase and makes it ever harder for us to walk around the design tree. Eventually, fresh competitors will be able to do it quicker and take our users.
Some decisions are practically unchangeable
At some point, we may also discover a requirement that implies a different decision for a high-level design question, such as wanting to take the other branch in question c. These changes are extremely expensive because all of the subsequent decisions have depended on them. If we tear up c, we also have to tear up h-m-p. We may start a big rewrite project and then regret it, one way or another.
Again, rework ensues and we accrete more residue. Although we should change our decision in question c, there is no practical way to do it at this point. It’s really important to get high-level decisions right.
The paradox of high-level design questions
This, ultimately, leads us to what may seem like a paradox of product design.
- We need to focus on the high-level design questions first, because otherwise we will make incoherent detailed design decisions.
- It is important that we get the high-level design questions right, which we can only do if we postpone them for as long as possible.
There is a nuance here that is worth mentioning: not all high-level design decisions will change. It’s easy to find constants in any domain, or at least reliable relationships. These are sometimes called the fundamental laws of the domain and a big part of innovative product development is to discover them. Here are some dumb examples.
- Passwords are shared secrets. If we use password-based authentication, we need to be equipped to store valuable secrets.
- There will be bugs in our software, so there needs to be a way to patch them.
- Automation is capable of producing errors at a high rate.
- Network i/o is slower than local ram access – although the next fastest thing after “my ram” may well be “someone else’s ram on the same local network.”
- Humans don’t make sense of tables of many numbers. They need visual displays of quantitative data.
- Meteorologists need to be able to represent fronts in their weather visualisation software.
It’s fine to make decisions and write code that assumes these fundamental laws because they are unlikely to change. But there are also high-level decisions that are prone to be invalidated by changing requirements. How do we deal with that?
Reframing as program families
We have to take a step back. The key realisation is that we are not designing one program … and then we get unlucky and have to evolve it through time.
Instead, we start from the assumption that we will create several very similar programs. We will create a program family, in the terminology of Parnas3 On the Design and Development of Program Families; Parnas; ieee Transactions in Software Engineering; 1976.. We bake this fact into our design from the start. We account for not having the correct requirements (we never do) and we plan to create multiple versions of the product. This changes how we approach the design.
We still only create one product at a time, of course: the one that fulfills our best current guess of the requirements. But we build it in such a way that the other products we think we’ll need to build in the future are easy to build.
With this realisation, we start to think in modules.
Modularisation lets us encapsulate change
Any design questions where we anticipate the answer may change in the future, we don’t write code mirroring our decision right away. Instead, we figure out the interface that matches all possible decisions on that question, and write the code against that interface. The effect is that we are hiding our decision inside a module, and the rest of the code works against the interface of that module, completely oblivious to what the actual decision was.
If we hide the decision made on question h in our original a-c-(h)-m-t product, we still get the same product at first.
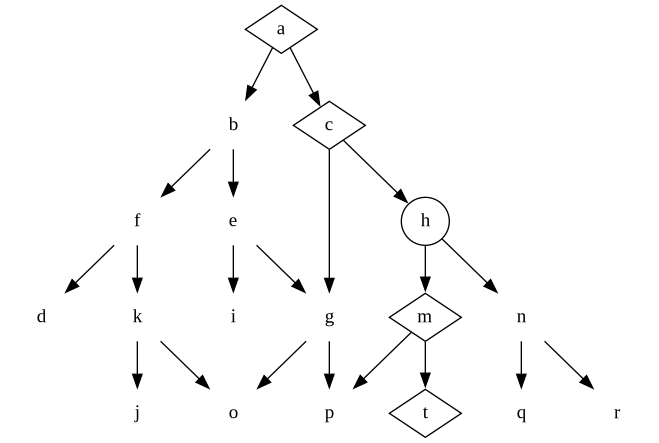
But then, when we realise we might want the a-c-(h)-n-q product instead, we don’t have to backtrack and rip up old decisions and rework the code. That branch will still work against the general interface we made to hide the decision h. We can build the missing pieces without having to change what already exists.
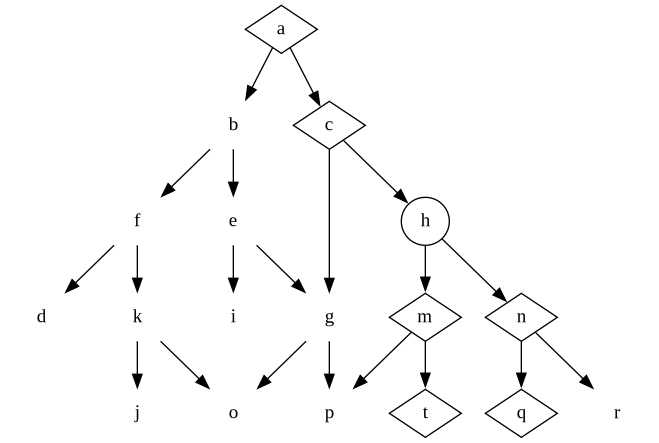
This is even more important for those high-level decisions. If we had encapsulated the decision at c in a module, we could create the program a-(c)-g-o without ripping up anything along the other branch, because none of g, h or any descendent decisions would be able to make any assumptions about the decision we made in c – that decision is hidden inside a module.
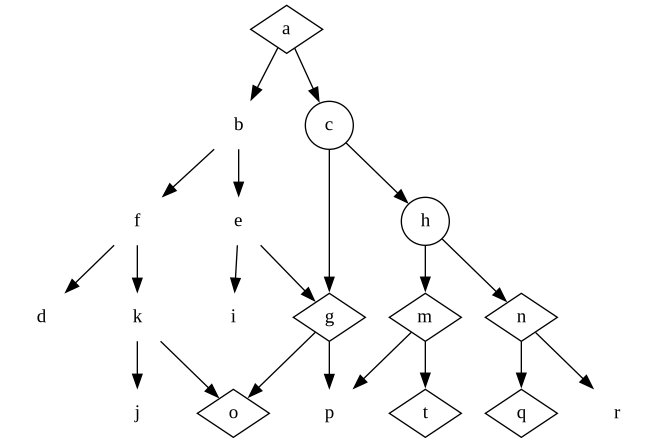
Which decisions to hide, and how?
There’s an obvious reason we don’t just hide every decision in their own modules: modules are more expensive than assumptions. Compared to straightforward assumptions, modules
- Take longer to create, because they need a general interface4 And if their interface is not quite general enough, they start to leak which is even worse.;
- Introduce abstract concepts the reader may not be familiar with; and
- Increase indirection in the code, making it harder to know what goes on.
We need to hide only some decisions – the ones that may change, and would be expensive to change if they were coded as assumptions rather than hidden in modules. So far, we have completely brushed over this difficult judgment, which is a broad enough topic to be an article of its own. We will look at that some other time.
Now that we know what modules are intended for, we also know what modules are not for.
- We don’t create a module just because we found a noun in the specification.
- We don’t split our software into two modules because two teams will be working on it.
- We don’t create 100 modules because we recently read about how great microservices are.
- We don’t create a new module because the source code in the current one is getting large.
We do create a module to hide a design decision we are forced to make before we are certain it’s not going to change, so subsequent decision decisions cannot make assumptions about this one.