Word Embeddings in Perl: Baby Steps
Table of Contents
Continuing from our adventures into latent semantic analysis in Perl, I have been toying with neural networks, the ultimate goal being word2vec-style word embeddings.1 Again, not because I think the outcome will be practically useful – there are pre-trained word2vec models for that – but because I need an excuse to do something I’ve never done before: write a neural network.
Hidden layer weights are word vectors
Computers are not good at comparing the meanings of words. They are good at comparing numbers. In order for computers to compare the meanings of words, we have to first translate the words into numbers that represent their meaning. These numbers are called word embeddings. In particulra, word2vec-style models use vectors of floating point values, or word vectors.
It’s trivial! Except we skipped over the part of the explanation where we drew the rest of the owl. How can we translate words into vectors where the vectors happen to lie close to each other when their corresponding words are similar in meaning?
You are defined by the friends you keep
The high level idea of word2vec is that words used in similar contexts are similar. We’ll find the words “fridge” and “freezer” in similar places in sentences, so those two words are likely related in some way.
One of the popular approaches is to train a neural network to predict neighbouring words. So if we give it e.g. the word “maintenance” it may predict that the surrounding words are likely to contain “package” or “burden”. If we give it the word “understanding”, it may predict that the surrounding words will contain “clearer” or “reached”.
Here’s the one weird trick: we pick a very specific shape for this neural network, namely one of three parts:
- Input vector: one-hot encoded word given as input.
- Hidden layer with k neurons.
- Output vector: softmax scaled prediction of neighbouring words.
Now when the network is trained to predict neighbouring words, each possible input word will be associated with weights that control the vaules of the hidden layer for that word. Those weights become the vector for that word. That’s how word embeddings are extracted from the neural network.
The hidden layer encodes general concepts
Intuitively, we can imagine the hidden layer as encoding the underlying concept the input word corresponds to, and the neural network uses that underlying concept to guess what the neighbouring words are. This means the word vector will be a representation of what general concept a word belongs to. So for the example of the word “fridge”, the underlying concept may include elements of noun, appliance, common item, large, etc.
This also explains why we can use the weights from the hidden layer as word vectors: when comparing those word vectors, we are really comparing the underlying general concepts!
By reducing the number of neurons in the hidden layer, we can force a dimensionality reduction in the concept space.
Reading input–output pairs into a matrix
We can reuse some of the code from before to generate a list of significant terms, as well as generate a long list of pairs of such words that occur in close proximity to each other in the articles on this site. Then creating an input and an output matrix of one-hot coded words is not technically complicated:
# %important contains all significant words, so $vocab_width # is the total number of words in the vocabulary. my $vocab_width = scalar keys %important; # This limit exists to train on a subset of pairs only, because # the full set of pairs would take a long time to properly # train on. my $max_samples = 5000; my $inputs = zeroes $vocab_width, $max_samples; my $outputs = zeroes $vocab_width, $max_samples; open $fd, '< :encoding(UTF-8)', '30_pairs.txt'; $i = 0; while (defined ($_ = <$fd>) && $i < $max_samples) { chomp; my ($in, $out) = split ',', $_; # Get word indices of word pair. (my $ini, my $outi) = ($important{$in}, $important{$out}); # One-hot code this word pair. $inputs($ini, $i) .= 1; $outputs($outi, $i) .= 1; $i++; } $max_samples = $i if $i < $max_samples;
No hidden layer is sort of logistic regression
When we have never done something before, it’s usually a good idea to try to break the problem into smaller chunks and solve one at a time. I had never written a neural network before, so I opted to start with the simplest neural network that still, sort of, resembled the original task I wanted to solve.
That meant ignoring the hidden layer. In otehr words, the first model was input layer, hrough only one set of weights, directly to the output layer, and then softmax on top of that.
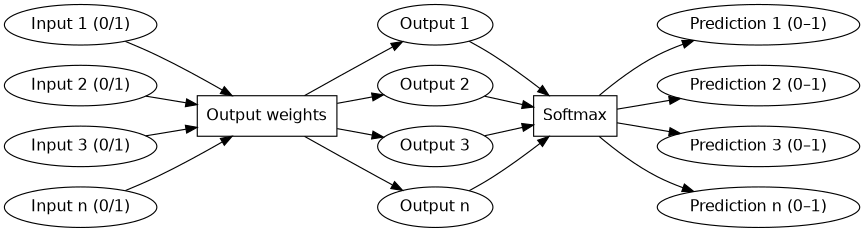
Besides making the implementation eaiser to figure out, this simpler model would also be easier to interpret, debug, and understand.
The forward pass is not too complicated once we are familiar with some of the basic linear algebra it’s usually described in terms of. We initialise the model with random weights, and then the forward pass consists of
- Multiply input one-hot vector with weight matrix.
- Run softmax over the output.
Done!
However, to determine how well the network has predicted neighbouring words, we also add another step where we evaluate the cross-entropy of the output and the actual neighbouring word in this training pair. That means the full forward pass including evaluation looks like
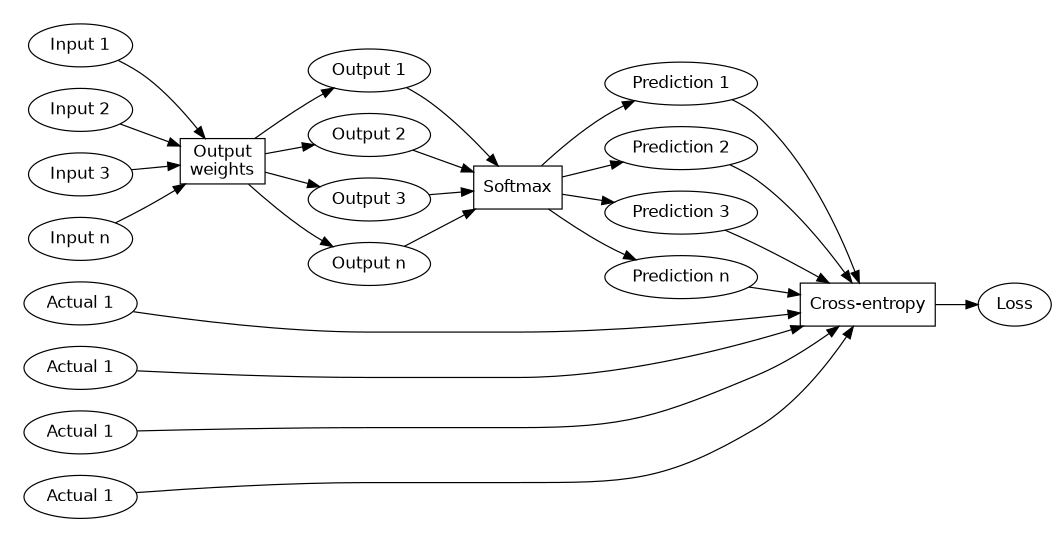
This looks messy but it’s not that complicated once you see the structure. We can also write it as a series of function applications:
output = output_weights(input) prediction = softmax(output) loss = cross_entropy(actual, prediction)
or, in chained form
loss = cross_entropy(actual, softmax(output_weights(input)))
The initial Perl draft I threw together for this is no longer with us, but we will see the code for these operations including the hidden layer shortly.
Gradient descent and backpropagation
The idea of gradient descent makes complete sense: if someone tells us in which direction to nudge the inputs of a function to reduce loss, then obviously we just nudge inputs in that direction. The gradient is the mathematical operation that produces the information on which direction to nudge inputs in.
Computing the gradient is usually done through backpropagation.
The idea of backpropagation also makes complete sense. A neural network is really just chained matrix multiplications and activation functions (see above). To compute the gradient of chained function applications, we can do it one step at a time. We could do it forwards, but doing it backwards makes sense from a dynamic programming perspective, because it allows us to reuse results from previous computations.
Then comes actually implementing it in practise. It’s definitely not rocket surgery, but – at least for me – it really required concentration and a good chunk of pencil-and-paper thinking.
Predicting neighbouring words
But, then, suddenly2 These things always seem to happen suddenly to me. I have no sense of how far off success still is – I’m just working through bugs and understandings until, well, suddenly it works., there it was! A neural network that could predict neighbouring words from a small set of training pairs.
I can’t find any output from this version, but it was exhilerating to have something working, simple as it was. With a small enough vocabulary, it could perfectly predict the other half of the word pairs I fed it.3 In other words, its reliability was excellent; it’s (external) validity was abysmal. That’s part of the purpose of the hidden layer. By going through concepts, it makes the network a little bit more robust. That’s a low bar to clear, but it was my first neural network. And it worked.
Adding a hidden layer
At this point, it might seem like it would be trivial to add the hidden layer. After all, there’s nothing conceptually new about it. All the (to me) uncertain parts had already been implemented.
I spent way longer on adding the hidden layer than I care to admit. It wasn’t the forward pass (that’s “just” another matrix multiplication), but for some reason the additional layer threw me for a loop when it came to backpropagation.4 I think maybe it was something relating to the fact that whereas I previously only needed the gradient with respect to the output weights, I now also needed the gradient with respect to the output values.
Here is the shape of the network, without the cross-entropy loss evaluation. (Imagine it being there if it helps.)
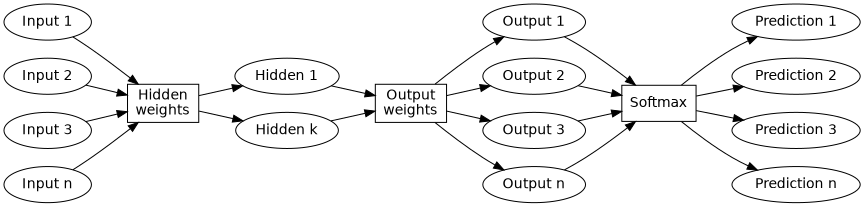
Initialising neural network
The network is – if we ignore its structure5 There’s an alternative architectural choice here: make the structure part of the network data. That is the far more general implementation, but I was aiming for quickly implementing a specific network, not generality. The 2020-era word2vec type network will never change, so there’s no point in making code that can adapt to such change! – defined by just two things: the weights used when going from input to hidden layer, and the weights used when going from hidden to output layer. That results in a short function to create the network:
sub init_network { my $w_hidden = ones $vocab_width, $concept_width; my $w_out = ones $concept_width, $vocab_width; for (0..1000) { $w_hidden(int(rand($vocab_width)), int(rand($concept_width))) .= rand(); $w_out(int(rand($concept_width)), int(rand($vocab_width))) .= rand(); } return { w_hidden => $w_hidden, w_out => $w_out, }; }
Note that in this implementation, we have been lazy and not bothered looking up how to create a matrix initialised to random values. Instead, we look up 1000 random locations in the matrices and set those to random values.
Forward pass through network
This is one of the simpler steps: multiply the matrices and apply softmax to the output layer. The intermediate values are all returned since at least some of them will be needed to compute gradients.
sub forward_network { my ($network, $input) = @_; my $hidden = $network->{w_hidden} x $input; my $output = $network->{w_out} x $hidden; my $prediction = $output->exp / $output->exp->sum; return { input => $input, hidden => $hidden, output => $output, prediction => $prediction, }; }
In the code, we will see some confusing names used. The layer that sits between the hidden layer and the prediction is named output. The same name is used for the second half of the training data pairs! This did lead to some mistakes, but not enough that I bothered going through the code and renaming one of the things.
Scoring of network prediction
It seemed sensible to me to implement the scoring of the prediction as a separate function, because then we can run th enetwork forward with only an input word. This computes the cross-entropy of the prediction and the output part of the training pair.
sub evaluate_forward { my ($forward, $output) = @_; my $loss = - sum ($output * $forward->{prediction}->log); return { forward => $forward, output => $output, loss => $loss, }; }
Backpropagation to compute gradients
This part of the code was by far the trickiest to get right6 And to be honest, not entirely sure I have gotten it completely right in the published code here, either.. To avoid accidentally writing a how to backpropagation tutorial here (see links at the bottom of this article), let’s just see the code and move on.
The variables named d_x_y refer to the gradient of x with respect to y. The
terms whidden and wout are the weights associated with the hidden and output
layers respectively.
sub propagate_backward { my ($network, $evaluation) = @_; my $d_loss_pred = - $evaluation->{output} * 1/$evaluation->{forward}{prediction}; my $d_pred_out = do { my $i_v = identity $vocab_width; my $s_i = $evaluation->{forward}{prediction}->dup(0, $vocab_width); my $s_j = $evaluation->{forward}{prediction}->transpose->dup(1, $vocab_width); $s_i * ($i_v - $s_j); }; my $d_loss_out = $d_pred_out x $d_loss_pred; my $d_out_wout = $evaluation->{forward}{hidden}->transpose->dup(1, $vocab_width); my $d_loss_wout = $d_out_wout * $d_loss_out; my $d_out_hidden = $network->{w_out}->transpose; my $d_loss_hidden = $d_out_hidden x $d_loss_out; my $d_hidden_whidden = $evaluation->{forward}{input}->transpose->dup(1, $concept_width); my $d_loss_whidden = $d_hidden_whidden * $d_loss_hidden; return { d_loss_whidden => $d_loss_whidden, d_loss_wout => $d_loss_wout, }; }
This part of the code is by far the slowest part. When profiling, the
computation of $d_pred_out really stood out as slowest of them all.7 Turns
out it’s very expensive to create huge matrices only to multiply most of them
away again. Who would have thought? I created a slightly optimised version of
that computation that computes $d_pred_out directly without any intermediate
states, and the computation for that variable looks like
my $d_loss_out = do { my ($i) = @{unpdl which $evaluation->{output}}; my $p = $evaluation->{forward}{prediction}->copy; my ($d_loss_pred_ish) = @{unpdl (-1/$p(:,($i)))}; my $d = zeroes $vocab_width; $d($i) .= 1; $d = $d->transpose - $p(:, ($i))->dup(1, $vocab_width); $p = $p * $d; $p * $d_loss_pred_ish; };
This is a bit tricky to follow, but it’s based on the fact that the output word is one-hot encoded, so the cross-entropy loss is zero for almost all components of the prediction except in one location.
The important part is that it improved training time by almost a factor of 20! With the slower code, training 1000 pairs takes 30 seconds, and with the newer code it takes just under two seconds.
Gradient descent to update weights
Once we have the hard-earned gradients for the weights, the actual update to walk down the gradient is a matter of arithmetic. Since the gradient points upslope (toward higher loss), we apply a small fraction of negative gradient to shimmy downslope.
sub gradient_descent { my ($network, $gradients) = @_; my $step_size = 0.01; my $w_hidden_next = $network->{w_hidden} + -$step_size * $gradients->{d_loss_whidden}; my $w_out_next = $network->{w_out} + -$step_size * $gradients->{d_loss_wout}; return { w_hidden => $w_hidden_next, w_out => $w_out_next, }; }
Tying together by calling everything in sequence
Calling these functions in sequence yields an iteration of training. We can do these iterations many times to hopefully get something sensible.
my $n = init_network; for my $iters (0..$max_iters-1) { # Pick a random word pair to train on. my $word = int(rand($max_samples)); # Input the word and run the network forward. my $f = forward_network $n, $inputs(:, ($word))->transpose; # Compare to the actual output and compute cross entropy loss. my $e = evaluate_forward $f, $outputs(:, ($word))->transpose; # Run backpropagation to find relevant gradients. my $d = propagate_backward $n, $e; # Apply gradients to nudge weights in the right direction. $n = gradient_descent $n, $d; }
Example run
On a rather small vocabulary, these are a couple of examples for which the neural network predicts neighbouring words.
vocabulary size: 88 words
hidden layer size: 10 neurons
training data size: 4000 word pairs
training time run: 340000 iterations
forward: 35 seconds
evaluate: 30 seconds
backprop: 146 seconds
graddesc: 20 seconds
Top predicted for throughput:
idle (0.282926072456738)
queueing (0.203447311429027)
lambda (0.150047726808125)
approx (0.0677357006513723)
perl (0.0279980203695144)
Top predicted for parsers:
readp (0.320780649913162)
monad (0.253496002428353)
wind (0.201488443337817)
sensitivity (0.0437110736151976)
loops (0.040039343569064)
These predictions may not all seem entirely sensible out of context, but noting that they come from articles on this site, they seem rather sensible – I can point to the exact articles in which these pairs co-occur.
Problems and solutions
I have already encountered a few annoying problems during this process.
Garbage in, garbage out
For a while I had what I thought was a working neural network, except it kept predicting nonsense. I tried adjusting parameters, trying to train it for longer, reduced the vocabulary to just a few words, but nothing helped. After spending way too long trying to find a problem in the backpropagation, I realised I had given the network a nonsense vector for the input, rather than the one-hot vector corresponding to the word I thought I had asked it to predict.
This is a really good lesson. When code misbehaves, it’s almost always due to a bug in the code, rather than faulty input, so it’s easy to develop a heuristic to start debugging immediately. However, checking for faulty input is so much easier than debugging code that works, so it’s still a better first response to verify the input, on the off chance that this was one of those one-in-a-hundred times when the input really is the problem.
Slow code
We saw one optimisation in the section on backpropagation. I often profile code manually, by injecting counting logic in the code I suspect is slow, and then analyse the rates at which things happen.
For this code, I tried Perl’s NYTProf. It was a magical experience. It showed
not only which functions were slower than the rest, but also which statements
were slow. It even displayed which parts of each statement was slow!
Without that, it would have taken me much longer to figure out that the
innocent-looking statement $s_i * ($i_v - $s_j) was the main cause of slow
execution8 Blessing and curse of working with matrices. We get low-effort
vectorisation, but it’s also easy to accidentally work on huge data structures
without it being obvious in the code.. Optimising that statement away made
training go 20× faster.
Adjustment and evaluation
At this point there’s a neural network that seems to work for very small vocabularies. Adding more words makes it stop working. This is to be expected, if nothing else because more words means it needs to train for longer.9 Actually, we can also tweak the learning rate and the width of the hidden layer. This article is long enough already. Maybe we’ll take some time to explore that later.
The end goal is to run this network on at least 2000 words, ideally more. How much training will it need to work with that? But wait, let’s back up a little.
What does it even mean for it to work? I don’t know, to be honest. we can eyeball some predictions and say whether they look right or wrong, but that doesn’t scale. One idea is to select a few words randomly, and see how likely the top prediction candidates for those words are. If we look at a large enough number of candidates, their total probability should start out low but grow to near 100 % as training goes on. When it approaches 100 %, we might interpret that as the model having learned what those words are associated with.
To get a sense of when this happens, we can write a script that randomly walks
around in the parameter space10 In a throwback to the previous article, the
parameter space is actually the pair of numbers min_usages and min_idf from
before, which determines which words are considered significant. and for each
new position, it runs the neural network until it has learned the five random
words.
I was hoping to present a pretty graph, but the data is incredibly noisy.
Rather unsurprisingly, the number of training samples extracted from the articles on this site varies with the square of the size of the vocabulary of significant words.11 Whenever you have x things, you always have O(x²) pairs of things.
The speed at which the network converges might look like it, maybe, on very shaky data, decays exponentially in log-iterations12 That already sounds like bad news!. It starts out improving by almost 30 percentage points per log-iteration for the smallest data sets, but then as we get to 4000 sample pairs, it’s already down to 10 percentage points per log-iteration. At 15,000 sample pairs, it’s around 5 percentage points per log-iteration.
The vocabulary of 2000 words turns into 275753 pairs. According to the –
eyeballed – improvement model described above, these pairs would improve at a
rate of percentage points per log-iteration. That’s a total of
log-iterations until it’s learned, which R helpfully tells me is Inf
iterations. I don’t want to wait for that.
I suspect there’s a flaw in the evaluation strategy that generated the data in this section13 The nuance lies in the idea of “a large enough number of candidates” – I hard-coded this to five, which is probably not large enough for large vocabularies! It may also be the cause of it over-estimating the learning rate for small vocabularies., and that the network actually learns faster than that. These investigations may end up in a separate article.
Useful links
Here are the references I consulted most often regarding building neural networks: